plf:: library and this page Copyright (c) 2021, Matthew Bentley.
Last updated 2-2-2021, plf::colony v6.11, plf::list v1.85. Sort and list-specific benchmarks updated 25-06-2020 with plf::colony v5.34, plf::list v1.74.
The test setup is an an Intel Xeon E3-1241 (Haswell core), 8GB ram, running mingw GCC 9.2 x64 as compiler. OS is a stripped-back Windows 7 x64 SP1 installation with most services, background tasks (including explorer) and all networking disabled. Build settings are "-O2 -march=native".
The source code for the benchmarks can be found in the colony page downloads section.
The first (roughly) 10% of all test runs are discarded in order to 'warm up' the cache and get statistically-meaningful results. Tests are based on a sliding scale of number of runs vs number of elements, so a test with only 10 elements in a container may average 100000 runs to guarantee a more stable result average, whereas a test with 100000 elements may only average 10 runs. This tends to give adequate results without overly lengthening test times. I have not included results involving 'reserve()' as yet.
Insertion: is into empty containers for the raw tests, entering
single elements at a time. For the 'scenario' tests there is also ongoing
insertion at random intervals.
Erasure: initially takes place in an iterative fashion for the raw
tests, erasing elements at random as we iterate through the container. The
exception to this is the tests involving a remove_if pattern (pointer_deque and
indexed_vector) which have a secondary pass when using this pattern.
Iteration: is straightforward iteration from the start to end of any
containers. Typically there are more runs for iteration than the other tests
due to iteration being a much quicker procedure, so more runs deliver a more
stable average.
Before we begin measuring colony against containers or container modifications which do not invalidate links on erasure or insertion, we need to identify which containers are good candidates for comparison based on raw performance without regard to linkage invalidation. With that in mind the following tests compare colony against the main standard library containers. Tests are carried out on the following types: (a) a 8-bit type ie. char, (b) a 32-bit type ie. int, (c) a 64-bit type ie. double, (d) a small struct containing two pointers and four scalar types (40 bytes on x64), and (e) a large struct containing 2 pointers, 4 scalar types, a large array of ints and a small array of chars (490 bytes on x64).
The first test measures time to insert N elements into a given container, the second measures the time taken to erase 25% of those same elements from the container, and the third test measures iteration performance after the erasure has taken place. Erasure tests avoid the remove_if pattern for the moment to show standard random-access erasure performance more clearly (this pattern is explored in the second test). Both linear and logarithmic views of each benchmark are provided in order to better show the performance of lower element amounts.
Erasure tests forward-iterate over each container and erase 25% of all elements at random. If (due to the variability of random number generators) 25% of all elements have not been erased by the end of the container iteration, the test will reverse-iterate through the container and randomly erase the remaining necessary number of elements until that 25% has been reached.
Click images or hover over to see results at linear scale instead





plf::colony and plf::list show strong insertion performance, with plf::colony slightly out-performing. std::vector performs well for small types, and std::deque performs well until large structs (libstdc++'s deque implementation has a memory block limit of 512 bytes, making it a glorified linked-list in that scenario). Libstdc++'s deque implementation allocates on initialization, not on first insertion, which gives it the advantage for low numbers of non-large elements as above. plf::list generally outperforms std::list by 333% on average.
Click images or hover over to see results at linear scale instead





Without remove_if std::deque and std::vector perform poorly, with it they perform well until the size of the element becomes larger than 8 bytes. plf::colony and plf::list lead performance overall. plf::list has the best erasure performance until very large amounts of memory are involved and then becomes equal to std::list.
Click images or hover over to see results at linear scale instead





std::vector easily has the best iteration performance, although for all but large structs std::deque has almost equal performance. This is because of libstdc++'s deque implementation's 512-byte block limit. plf::colony comes in third for larger-than-scalar types, while plf::list comes third for scalar types.
This is an additional test purely for colony. Colony is primarily designed for scenarios where good insertion/erasure/iteration performance is required while guarantee'ing stability for outside elements referring to elements within the container, and where ordered insertion is unimportant. The two containers from the raw performance tests which may compare both in performance and usage (after modification) are std::deque and std::vector. std::list does not meet these requirements as it has poor insertion and iteration performance. plf::list does, but it's comparitive performance is already known so will not be included here.
Because std::deque does not invalidate pointers to elements upon insertion to the back or front, we can guarantee that pointers won't be invalidated during unordered insertion. This means we can use a modification called a 'pointer-to-deque deque', or pointer_deque. Here we take a deque of elements and construct a secondary deque containing pointers to each element in the first deque. The second deque functions as an erasable iteration field for the first deque ie. when we erase we only erase from the pointer deque, and when we iterate, we iterate over the pointer deque and access only those elements pointed to by the pointer deque. In doing so we reduce erase times for larger-than-scalar types, as it is computationally cheaper to reallocate pointers (upon erasure) than larger structs. By doing this we avoid reallocation during erasure for the element deque, meaning pointers to elements within the element deque stay valid.
We cannot employ quite the same technique with std::vector because it reallocates during insertion to the back of the vector upon capacity being reached. But since indexes stay valid regardless of a vector reallocating, we can employ a similar tactic using indexes instead of pointers; which we'll call an indexed_vector. In this case we use a secondary vector of indexes to iterate over the vector of elements, and only erase from the vector of indexes. This strategy has the advantage of potentially lower memory usage, as the bitdepth of the indexes can be reduced to match the maximum known number of elements, but it will lose a small amount of performance due to the pointer addition necessary to utilise indexes instead of pointers. In addition outside objects refering to elements within the indexed_vector must use indexes instead of pointers to refer to the elements, and this means the outside object must know both the index and the container it is indexing; whereas a pointer approach can ignore this and simply point to the element in question.
We will also compare these two container modifications using a remove_if pattern for erasure vs regular erasure, by adding an additional boolean field to indicate erasure to the original stored struct type, and utilizing two passes - the first to randomly flag elements as being ready for erasure via the boolean field, the second using the remove_if pattern.
A second modification approach, which we'll call a vector_bool, is a very common approach in a lot of game engines - a bool or similar type is added to the original struct or class, and this field is tested against to see whether or not the object is 'active' (true) - if inactive (false), it is skipped over. We will also compare this approach using a deque.
packed_deque is an implementation of a 'packed_array', but using deques instead of vectors or arrays. As we've seen in the raw performance benchmarks, (GCC) libstdc++'s deque is almost as fast as vector for iteration, but about twice as fast for back insertion and random location erasure. It also doesn't invalidate pointers upon insertion, which is useful when designing a container which is meant to handle large numbers of insertions and random-location erasures. Although in the case of a packed-array, random location erasures don't really happen, the 'erased' elements just get replaced with elements from the back, so erasure speed is not as critical, but insertion speed is critical as it will always consume significantly more CPU time than iteration.
With that in mind my implementation uses two std::deque's internally: one containing structs which package together the container's element type and a pointer, and one containing pointers to each of the 'package' structs in the first deque. The latter is what is used by the container's 'handle' class to enable external objects to refer to container elements. The pointer in the package itself in turn points to the package's corresponding 'handle' pointer in the second deque. This enables the container to update the handle pointer when and if a package is moved from the back upon an erasure.
Anyone familiar with packed array-style implementations can skip this paragraph. For anyone who isn't, this is how it works when an element is erased from packed_deque, unless the element in question is already at the back of the deque. It:
In this way, the data in the first deque stays contiguous and is hence fast
to iterate over. And any handles referring to the back element which got moved
stay valid after the erasure.
Since neither indexed_vector nor pointer_deque will have erasure time benefits for small scalar types, and because game development is predominantly concerned with storage of larger-than-scalar types, we will only test using small structs from this point onwards. In addition, we will test 4 levels of erasure and subsequent iteration performance: 0% of all elements, 25% of all elements, 50% of all elements, and 75% of all elements.
Click images or hover over to see results at linear scale instead

plf::colony outperforms the others above 100 elements.
Click images or hover over to see results at linear scale instead



plf::colony comes in third, behind vector_bool and deque_bool.
Click images or hover over to see results at linear scale instead




Here we see that plf::colony's iteration performance is weaker than the others when no erasures have occured, but progressively becomes stronger than vector_bool and deque_bool as erasures increase. The drop in vector_bool and deque_bool's iteration performance around the 2500 element mark is likely to be due to the size limit of the Haswell processor's branch decision history table. When compared to the results on a Core2 processor (which has a very small branch decision history table), it becomes clear that vector_bool and deque_bool's iterative performance for low numbers of elements will drop as soon as there is competition for the CPU from multiple processes or multiple containers.
While testing iteration, erasure and insertion separately can be a useful tool, they don't tell us how containers perform under real-world conditions, as under most use-cases we will not simply be inserting a bunch of elements, erasing some of them, then iterating once. To get more valid results, we need to think about the kinds of use-cases we may have for different types of data, in this case, video-game data.
In this test we simulate the use-case of a container for general video game objects, actors/entities, enemies etc. Initially we insert a number of small structs into the container, then simulate in-game 'frames'. To do so we iterate over the container elements every frame, and erase (at random locations) or insert 1% of the original number of elements for every minute of gametime ie. 3600 frames, assuming 60 frames-per-second. We measure the total time taken to simulate this scenario for 108000 frames (half an hour of simulated game-time, assuming 60 frames per second), as well as the amount of memory used by the container at the end of the test. We then re-test this scenario with 5% of all elements being inserted/erased, then 10%.
In these tests we will be measuring up to 100000 elements, as higher numbers use too much memory with the indexed_vector and pointer_deque containers.
Click images or hover over to see results at linear scale instead



pointer_deque and indexed_vector variants perform best for low numbers of elements, but past 2500 packed_deque and plf::colony take the lead. Overall packed_deque is slightly faster than plf::colony. plf::list performs poorly.



Understandably the pointer_deque and indexed_vector implementations consume more memory, as they cannot free it on the fly. colony's usage of memory is more or less equivalent to packed_deque, but expands more slowly. plf::list has slightly more usage for lower numbers of elements, becoming equal above ~10000 elements.
Same as the previous test but here we erase/insert 1% of all elements per-frame instead of per 3600 frames, then once again increase the percentage to 5% then 10% per-frame. This simulates the use-case of continuously-changing data, for example video game bullets, decals, quadtree/octree nodes, cellular/atomic simulation or weather simulation.
Click images or hover over to see results at linear scale instead



Here we see packed_deque taking the lead for 1% erasures, while plf::colony takes the lead otherwise. plf::list has good performance until around 2500 elements - assumably the limit of the Haswell branch decision history table - at which point it's jumps can no longer be cached and overall performance declines. The remove_if variants of pointer_deque and indexed_vector vastly outperform their non-remove_if alternatives.



Results here are very similar to the low modification results.
These tests are primarily for plf::list. Here we repeat the low modification test previously displayed, but with ordered (non-back) insertion as well as non-back erasures. Since linked lists excel at non-back insertion we can expect to see different performance results to the unordered tests above. We will ignore memory results as these have already been explored above. The only new container introduced here is "pointer_colony" - a modification of plf::colony to allow for ordered usage. What it does is very similar to the pointer_deque - there is a deque of pointers to elements within the colony, whose locations stay stable because a colony never invalidates pointers to non-erased elements. However unlike the pointer_deque, the pointer_colony will free up and re-use erased element memory on the fly, meaning you will not have the memory bloat associated with the indexed_vector and pointer_deque.
Since we already established in the unordered tests above that the remove_if idiom performs worse in low modification scenarios, we include only non-remove_if variants in this test. It should be noted that while these results are for small structs, the same tests involving int's performed almost exactly the same in terms of performance differences between containers and gave the same overall results.
Click images or hover over to see results at linear scale instead



plf::list out-performs std::list by roughly 25% on average, but is outperformed by everything else. std::deque has the best performance with std::vector close behind.
Here we repeat the high modification test, but with ordered insertion. Since we have already established in the unordered tests that remove_if variants work better in the high modification scenario, we include only those results here.
Click images or hover over to see results at linear scale instead



plf::list outperforms all the other containers at high levels of modification. Again, the difference in performance between std::list and plf::list is about 25% on average.
In order to completely test plf::colony against a packed-array-style implementation, it is necessary to measure performance while exploiting both container's linking mechanisms - for colony this is pointers or iterators, for a packed array this is a handle, or more specifically a pointer to a pointer (or the equivalent index-based solution). Because that additional dereferencing is a performance loss and potential cache miss, any test which involves a large amount of inter-linking between elements in multiple containers should lose some small amount of performance when using a packed_deque instead of a colony. Since games typically have high levels of interlinking between elements in multiple containers (as described in the motivation section), this is relevant to performance concerns.
Consequently, this test utilizes four instances of the same container type, each containing different element types:
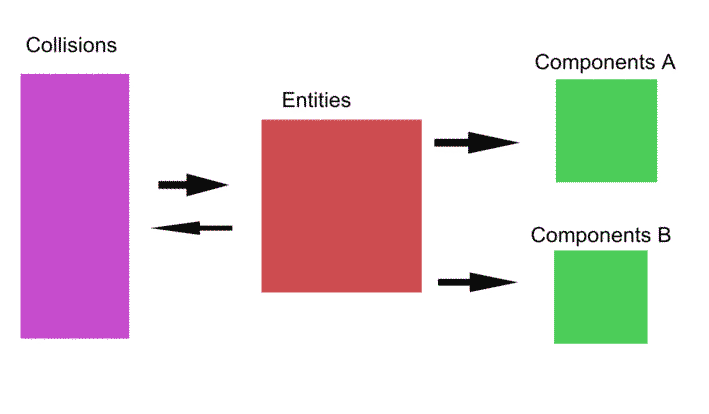
This is actually a very low number of inter-related containers for a game, but we're reducing the number of components in this case just to simplify the test. Elements in the 'entities' container link to elements in all three of the other containers. In turn, the elements in the collisions container link back to the corresponding elements in the entities container. The subcomponent containers do not link to anything.
In the test, elements are first added to all four containers and interlinked (as this is a simplified test, there's a one-to-one ratio of entity elements to 'collision' and subcomponent elements). The core test process after this point is similar to the modification scenarios tested earlier: we iterate over the entity container once every frame, adding a number from both the entities and subcomponents to a total. We also erase a percentage of entities per-frame (and their corresponding subcomponents and collision blocks) - similar to the earlier tests.
However during each frame we also iterate over the 'collisions' container and erase a percentage of these elements (and their corresponding entities and subcomponents) at random as well. This could be seen as simulating entities being removed from the game based on collisions occurring, but is mainly to test the performance effects of accessing the subcomponents via a chain of handles versus a chain of pointers. Then, again during each frame, we re-add a certain number of entities, collision blocks and subcomponents back into the containers based on the supplied percentage value. Since both colony and packed_deque essentially re-use erased-element memory locations, this tests the efficacy of each containers mechanism for doing so (packed_deque's move-and-pop + handle free-list, versus colony's stack + skipfield).
Since neither container will grow substantially in memory usage over time as a result of this process, a longer test length is not necessary like it was for the earlier modification scenario-testing with indexed_vector and pointer_deque. Testing on both plf::colony and plf::packed_deque showed that both of their test results increased linearly according to the number of simulated frames in the test (indexed_vector and pointer_deque have a more exponential growth). Similarly to the modification tests above, we will start with 1% of all elements being erased/inserted per 3600 frames, then 5% and 10%, then move up to 1% of all elements being erased/inserted per-frame, then 5% per-frame, then 10% per-frame.
Click images or hover over to see results at linear scale instead






For all results plf::colony outperforms packed_deque.
std::vector and std::deque are by default sorted using std::sort, while
plf::list and std::list are sorted using their internal sorting functions
(which change pointers only, not element reallocation).
plf::colony is a bidirectional container, so cannot use std::sort natively and
uses a form of plf::indiesort internally.
Comparisons are also provided for vector, deque and std::list, using
plf::indiesort.
We first examine sorting across small ranges, up to 10000 elements:
Click images or hover over to see results at linear scale instead





Overall we see that for scalar types, vector + std::sort has the best
performance, with plf::list and std::deque tied in second place for the most
part. Again for scalar types, using plf::indiesort with std::list is faster
than it's own internal sort function.
For small structs (48 bytes) deque and std::list lag behind, vector is 1st,
plf::list is second. At this point deque + indiesort outperforms deque +
std::sort.
For large structs (496 bytes) plf::list dominates, with colony + indiesort,
deque + indiesort and std::list in 2nd place. At this point std::list with
indiesort performs worse, as the type is large so merely writing pointers is
faster than reallocating elements with indiesort.
Deque & vector + std::sort perform the worst, being the technique involving
the most element reallocation.
Now we examine results with larger numbers of elements, up to 1000000:





For much greater numbers of elements vector and deque + std::sort are in
first and second place respectively for all types except large structs, at
which point they perform the worst and plf::list performs the best.
Performance of colony, deque and vector + indiesort are more or less tied,
being 2nd in place for large structs and in the middle for other types. The
performance of std::list's internal sort is generally much worse than std::list
+ indiesort across all types - presumably due to the much greater cache
locality of indiesort for large numbers of elements during the sorting
process.
plf::list is equal to std::vector for small structs and under about 3000
elements. It is also 77% faster than std::list's internal sort when averaging
all tests.
At this point I wanted to see where the cut-off points were for the increased performance of plf::indiesort with vectors and std::list's specifically. Small structs are 48 bytes on the testing platform, while large structs are 496 bytes. So I constructed a couple of in-between-sized structs, medium struct 1 and medium struct 2, at 152 and 272 bytes respectively. Here are the results for sorting (logarithm graphs only):




Here we can see that for std::list for anything under 272 bytes plf::indiesort outperforms it's own internal sort() function, with the downside that iterators to elements within the list become invalidated. 272 bytes seems to be the point at which .sort() and indiesort performance are equivalent.
For vector, the crossover point is at 152 bytes, where for smaller numbers of elements indiesort performs better, but larger numbers perform better with std::sort and on average they're about the same. Once you get to 272 bytes the performance difference is immediately apparent; 88% faster with indiesort on average.
Sorting is generally faster with vector + std::sort except when it comes to large structs. Then plf::list dominates results. std::list's internal sort performance is generally bad except for small numbers of large structs, but can generally be improved significantly using plf::indiesort for types smaller than 272 bytes. For types smaller than 272 bytes, std::list's performance is improved on average by about 28%.
For types larger than 152 bytes, deque and vector's sort performance can be
improved using indiesort, which is 130% faster on average for large structs.
However their results for types smaller than 152 bytes is worse using
indiesort.
Colony + indiesort is 2nd in place for large numbers of large structs,
std::list is second in place for small numbers of large structs.
Here we take a look at some results relating specifically to plf::list versus std::list. Namely reverse, remove, unique, clear and destruction. Results for remove_if should be the same as the results for remove. All benchmarks insert a number of ints with random values, iterate over the list erasing some percentage of elements at random, then perform the requisite function. The reason for randomly erasing some of the elements is that for some of these functions order is irrelevant to processing (eg. reverse merely flips previous and next pointers on nodes), and so plf::list takes advantage of this by linearly iterating over the memory blocks and skipping erased elements. So it is important to know how having some erased elements affects performance results.
Click images or hover over to see results at linear scale instead

plf::list outperforms std::list across the board. On average plf::list is 70% faster than std::list.

For remove/remove_if, plf::list is on average 91% faster than std::list.

On average, plf::list is 63% faster than std::list for unique.

For clear(), plf::list is between 12400% faster and 4500200% faster (on average 1147900% faster), depending on how many elements are in the list. Unlike std::list, plf::list's clear does not free up allocated memory blocks but instead reserves them for future insertions (an optional call to "free_unused_memory()" or "shrink_to_fit()" (slightly different semantics between those two functions but in this case they do the same thing) fulfills need for deallocation if necessary in the context). It should be noted that because the type stored in question (int) is trivially-destructible, individual processing of nodes is avoided in this context, at least for plf::list. The results will be different if non-trivially-destructible types and/or pointers are utilized. For the following benchmark we change the type to a non-trivially-destructible small struct:

Now we can see the std::list and plf::list results becoming closer together, with plf::list being on average 811% faster.

Unlike clear(), list destruction does of course free up allocated memory blocks for plf::list. plf::list is on average 6350% faster than std::list for destruction. In the benchmark above, both lists are unchanged after insertion. Lets see how those results alter once we sort the list elements prior to destruction, thereby disrupting the original linear sequence of elements in memory:

Essentially there is a bit less variance in plf::list's results but std::list's results for the largest number of elements quadruples. On average plf::list is 6500% faster than std::list here. We will also see a difference for destruction if the type in question is non-trivially-destructible - the following benchmark shows (non-sorted) destruction durations for lists with non-trivially-destructible small structs:

The results for destruction become closer together with the non-trivially-destructible type, with plf::list being 1248% faster on average.
While individual context graphs (insertion, erasure, iteration) can show interesting results, when the real-world situations which colony is designed for are taken into account, plf::colony outperforms other containers in unordered situations where elements are being inserted and removed on the fly while stable links (eg. iterators/pointers/indexes/etc) are maintained to non-erased elements.
plf::list shows better performance than std::list across all tests, and finds it's place in terms of overall container performance in ordered high-modification real-world tests. In this scenario it outperforms other containers, though at low levels of modification other containers are better choices. plf::list's sort performance is 77% faster than std::list on average, and has even stronger performance advantages for some of the less-used functions like reverse() and remove().
Both colony and plf::list are worthwhile considerations for replacing other containers within these contexts.
Contact:
plf:: library and this page Copyright (c) 2021, Matthew Bentley.